【翻译】 TensorFlow如何工作
学习TensorFlow过程中读的一篇文章,索性就翻译出来,虽然收获感觉不是很大。
原文地址:How TensorFlow Works
介绍
Google在2015年11越开源了TensorFlow系统。从那时起,TensorFlow成为了Github上Star数量最多的机器学习项目。
为什么选择TensorFlow?TensorFlow的流行有很多原因,最主要是因为计算图(computational graph)的概念、自动微分(automatic differentiation)以及TensorFlow 基于python的api结构的可适配性。这些特性使得广大程序员可以方便的使用TensorFlow解决现实中的问题。
Google的TensorFlow引擎采用了一种独特的解决问题的方式。该方式使得解决机器学习的问题非常高效。我们将通过一些基础的步骤来理解TensorFlow是如何工作的。理解TensorFlow的工作原理对于理解本书的余下部分十分必要。
TensorFlow如何运行
首先,TensorFlow中的计算看起来都不是复杂难懂。这是由于TensorFlow处理计算的方式使得开发复杂的算法变得简单。本文将会通过伪代码教会你TensorFlow中的算法是如何工作的。
TensorFlow目前兼容三大主流操作系统(Windows、Linux和Mac)。本书仅会介绍TensorFlow中封装的Python库。本书使用Python3.X(https://www.python.org)和TensorFlow0.12+(https://www.tensorflow.org)。TensorFlow可以运行在CPU上,当然在GPU上运行更快,兼容NVidia Compute Capability 3.0+显卡。如果想跑在GPU上,你需要下载安装NVidia Cuda工具包(https://developer.nvidia.com/cuda-downloads)。一些特性依赖于当前安装的Python包如:Scipy、Numpy和Scikit-Learn等。
TensorFlow算法总览
现在我们开始介绍Tensorflow算法的一般流程。大多数遵循下述流程。 1、导入或生成数据
所有的机器学习算法都依赖于数据。在本书中,我们既会生成数据也会使用外部数据。有时使用生成的数据更佳,因为我 们想要可预知的结果。其他情况下,我们会访问公共数据,第8部分会介绍这部分内容。
2、转换并标准化数据
原始数据通常都不处在TensorFlow需要的正确的维度或类型下。因此,在使用前需要进行转换。大多数算法还会需要标准化数据,我们也会在此时做这些事情。TensorFlow中有内置的函数可以帮助我们标准化数据。
1
data = tf.nn.batch_norm_with_global_normalization(...)
3、设置算法参数
我们算法通常会含有一组需要我们在程序中设置的参数。例如,迭代的次数,学习的速率或是其他我们选择的确定的参数。最好是一起初始化这些参数以便用户可以轻易的发现他们。
1
learning_rate = 0.01 iterations = 1000
4、初始化变量和占位符
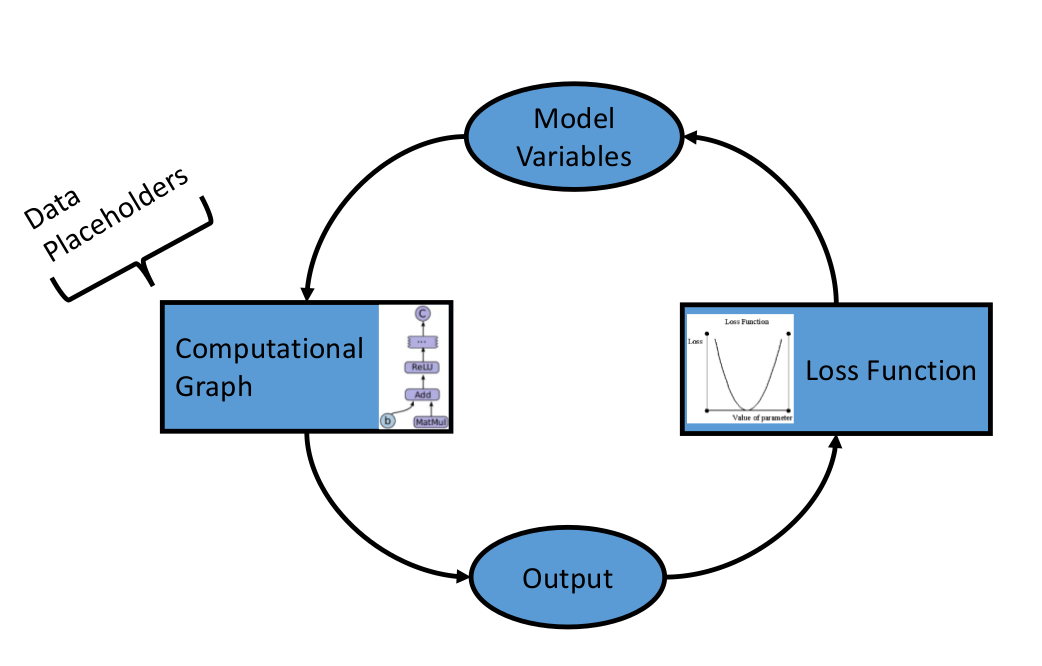
TensorFlow依赖于我们告诉它什么可以修改什么不可以修改。TensorFlow会在优化时修改变量,以最小化损耗函数。为了实现该目标,我们通过占位符提供数据。我们需要同时初始化变量和占位符的大小和类型,从而让TensorFlow知道预期的结果。
5、定义模型结构
在有了数据、初始化了变量和占位符之后,我们需要定义模型。这可以通过构造计算图来实现。我们告诉TensorFlow需要在变量和占位符上执行什么操作以达到模型的预期。
1
2
y_pred = tf.add(tf.mul(x_input, weight_matrix), b_matrix)
[ ]
6、声明损耗函数
定义模型后,我们必须评估输出。因此,我们需要声明损耗函数。损耗函数可以告诉我们预期结果和实际结果之间的差距。第二张第五部分会介绍不同类型的损耗函数。
1
loss = tf.reduce_mean(tf.square(y_actual – y_pred))
7、 初始化并训练模型
现在我们一切就绪,我们创建了一个实例或图并且通过占位符传入数据,然后让TensorFlow改变变量的值以更好的预测和训练数据。这里有一个初始化计算图的方式。
1
2
3
4
with tf.Session(graph=graph) as session:
...
session.run(...)
...
注意,我们也可以通过下面方式初始化图
1
session = tf.Session(graph=graph) session.run(…)
8、(可选)评价模型 当我们构建并训练模型之后,我们需要通过输入新的数据来评价模型在某些特殊场景下的运行情况。
9、(可选)预测新的输出 知道如何预期新的、从未见过的数据的产出同样重要。我们可以通过已训练的模型来进行预测。
总结
在TensorFlow中,我们需要在进行训练和改变变量前设置数据,变量,占位符和模型以提高预测的准确性。TensorFlow通过计算图完成此过程。我们令其最小化损耗函数,TensorFlow通过修改模型中的变量达到此效果。TensorFlow可以追踪模型的计算过程并且可以自动计算每个变量的渐变性,因此它知晓如何修改变量。也正是因为如此,我们可以发现在不同数据集上切换时非常简单。
总而言之,TensorFlow上的算法是被设计成可循环的。我们定义这种循环为计算图。(1)通过占位符传递数据,(2)计算计算图的输出,(3)通过损耗函数比较预期和实际输出的差距,(4)参考后台的自动迭代修改模型变量的值,最后(5)重复该过程直到达到结束条件。