事无巨细 Spark 1.6.1 集群环境搭建
还是在之前的Hadoop集群环境上继续搭建Spark-1.6.1环境
下载安装
下载Spark并解压
1
2
wget http://mirrors.cnnic.cn/apache/spark/spark-1.6.1/spark-1.6.1-bin-hadoop2.6.tgz
tar -xvzf spark-1.6.1-bin-hadoop2.6.tgz -C /home/dps-hadoop/
改个舒服的名字
1
mv spark-1.6.1-bin-hadoop2.6/ spark-1.6.1
配置环境变量
同样,修改.bashrc文件
1
vim ~/.bashrc
添加内容
1
2
export SPARK_HOME=$HOME/spark-1.6.1
export PATH=$PATH:$HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin
立即生效
1
source ~/.bashrc
配置Spark
拷贝一份配置文件模版
1
cp conf/slaves.template conf/slaves
修改slaves内容如下
1
2
3
master
slave15
slave16
其余走默认(这点来看,Spark真的很方便),将安装包拷贝到集群的其他节点。
1
2
scp -r spark-1.6.1/ slave15:~/
scp -r spark-1.6.1/ slave16:~/
启动集群
启动主节点
1
sbin/start-master.sh
启动从节点
1
sbin/start-slaves.sh
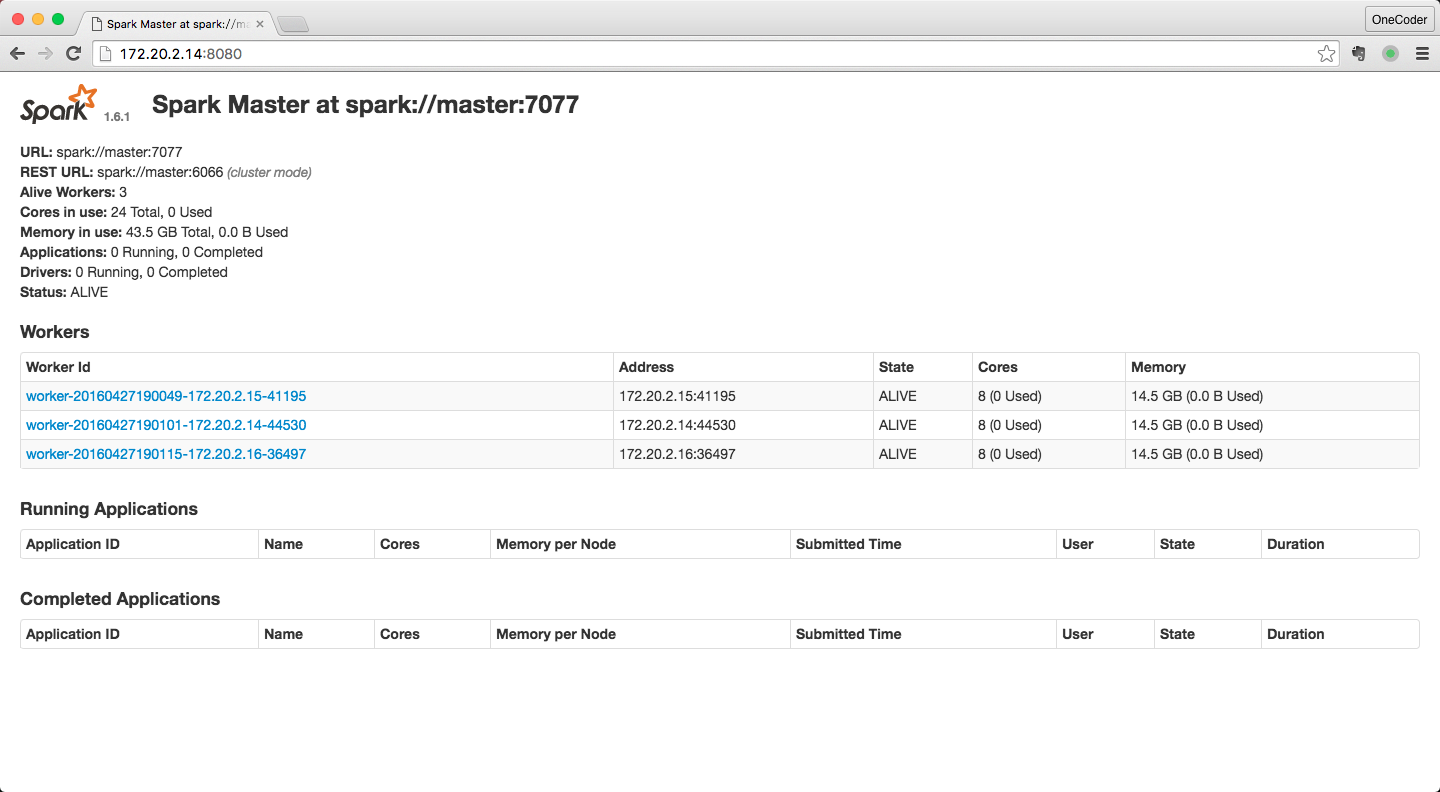
通过 Web UI查看,一切ok
本文由作者按照 CC BY 4.0 进行授权