OneCoder翻译 每个程序员必知的知识,UniCode和字符集(下)
接上篇:《《OneCoder翻译 每个程序员必知的知识,UniCode和字符集(上)》
- 原文地址:http://www.joelonsoftware.com/articles/Unicode.html
- 本文地址:http://www.coderli.com/translate-unicode-encoding-parttwo
好吧,从技术上讲,可以,我相信他可以。事实上,早起的实现者想用high-endian和low-endian两种模式保存Unicode字符码,不论哪种方式都是他们特定的CPU最快的处理方式。呵呵,夜以继日,现在就有了两种保存Unicode的方式。
所以人们不得不在每个Unicode串前强制的加上奇怪的约定:FE FF,这被称作Unicode字节顺序标识(OneCoder注:Unicode Byte Order Mark)。如果你交换了高低位的顺序,那将变成FF FE,读取你字符串的也将知道需要交换每一个字节。啊,不过不是每个Unicode字符串的开头都有字节顺序标识。

曾经,人们认为这足够好了,但是有些开发者却开始抱怨,看那一堆一堆的的0。是啊,因为他们是美国的开发者,他们仅关注英语文本,很少使用U+ooFF以上的编码。当然,这也是因为他们是来自加利福尼亚的对此不屑的自由的嬉皮士。如果他们是德克萨斯州人,他们可能不会在意消化两倍容量的字节。然而,加利福尼亚人无法忍受为字符串消耗两倍的存储空间,并且不管怎样,那已经有许多使用各种各样ANSI和DBCS字节码保存的令人厌烦的文档,谁能来改变这一切?摩伊人(Moi)?出于这个原因,大部分人放弃Unicode若干年,事情又变得糟糕起来。
因此,发明了美妙的UTF-8规范。UTF-8是另一种保存Unicode编码的系统,那些神奇的U+数字,在内存中使用8位字节。在UTF-8系统中,从0-127的每个字符码用一个单字节保存。128以上的编码,使用2个或者6,甚至6个字节保存。
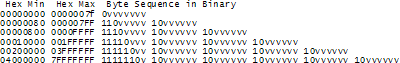
这种方式的优雅之处在于,得英文文字的保存在UTF-8和ASCII系统中完全一样,所以美国人没有表示任何问题。只是世界上剩下的人们不得不适应这个转变。特别的,Hello,Unicode码是:U+0048 U+0065 U+006C U+006C U+006F,将被保存为:48 65 6C 6C 6F,看!跟在ASCII中、ANSI中,甚至这个星球上每个OEM字符集中一致。现在,如果你有勇气去使用带有重音的字母或是希腊字母或是克林贡字母,你将不得不若干字节去保存一个字节码,但是美国人永远不会在意。(UTF-8还有一个很好的特性,就是旧的使用单独的0作为空结束符的字符串处理编码不会截断字符串。)
到目前为止,我已经讲解了三种Unicode的编码方式:传统的2个字节的保存方式,UCS-2(因为他有两个字节)或是UTF-16(因为他有16位),同事你仍必须认出是否他是high-endian的UCS-2还是low-endian的UCS-2。还有流行的新的UTF-8标准,该标准可以在你需要考虑英语和那些完全没有考虑ASCII以外编码的脑残程序的一致性方面,很好的工作。
事实上,还有很多Unicode的编码方式。例如:UTF-7, 和UTF-8很类似,只是最高位永远是0。所以,如果你需要给某些要求苛刻的,认为7位已经足够的警察email系统传递Unicode,感谢你仍可以无损的压缩字节。还有UCS-4,用4个字节保存每个字符码。好处就是每个字符都占用同样多的字节,但是,天啊,德克萨斯人们又无法忍受浪费这么多内存。
其实我们现在考虑的用Unicode展现的字符都是那些理想的字符,这些Unicode字符码同样也可以在任何的老派的编码系统中编码出来。例如:你可以给Hello进行Unicode编码(U+0048 U+0065 U+006C U+006C U+006F),进行ASCII编码或者古老的OEM希腊编码,或者希伯来ANSI编码,或者其他成百上千的编码方式。但是有一点需要注意:有一些字符无法展现!如果在Unicode字符码中没有与之对应的编码,例如,你常用遇到问号:?或者 � ,我改如何去做。
有成百上千的传统的编码仅仅可以保存正确编码,其余的全部转换成问号。一些流星的英语编码方式是Winodws-1252(Windows9.x系列的西欧语言的编码标准)和ISO-8859-1,又叫Latin-1(也是处理西欧语言的有效方式)。但是,如果尝试用这些编码保存俄罗斯或者希伯来语,你将会得到一堆的问号。UTF7,8,16和32都有很好特性,可以保存任何正确的编码。
编码最重要的事实
如果你已经完全忘记了我前面阐述的东西,请记住一个重要的事实。如果他不知道你使用的编码方式,那将无法工作。你不可能把你的头埋在沙子里,然后假装说”普通”(plain)文本是ASCII的。
没有所谓纯文本的东西。
如果你有一段字符串,不论在内存里还是文件里或是在email中,你必须要知道他的编码方式,否则你将无法解析和正确展示他。
几乎所有的关于”我的网站看起来乱码了”或是”当我在邮件里用带音调的字母的时候她就无法阅读了”这样愚蠢的问题,都是发生在那些不懂得上面关于编码的简单的事实的幼稚的程序员身上:如果你不知道字符串是用UTF-8或是ASCII或是ISO8859-1(Latin 1)还是Windows1252(Western European)编码,你就无法正确的展现它,甚至不知道他的结尾在哪里。有超过一百的编码和高127位的处理方式,一切猜测都没有用。
那么,我们怎么保存字符串所使用的编码类型的信息呢?呵呵,这有一个标准的方式。例如对于邮件信息,你希望在邮件头里看到类似这样的一串字符串:
Content-Type: text/plain; charset=”UTF-8”
对于网页,原来的想法是web服务器在web页面本身返回一个类似的 Content-Type头信息,不是在HTML页面本身,而是作为相应头在HTML页面之前返回。
这引发了一些问题。试想一下,你有一个大型的web服务器,里面有很多站点和非常多的页面,为说各种语言的人们服务,并且页面使用了适合他们的编码来读微软的FrontPage页面编码。Web服务器本身无法知道每个文件编写时的真正编码,所以他无法发送Content-Type头信息。
所以,如果你可以通过一些特殊的标签,把Context-Type信息放到HTML页面本身那将非常方便。当然,这会使那些有纯粹主义者疯狂…
在你知道HTML文件编码之前,你怎样去阅读他?幸运的是,几乎所有通常使用的编码在32-127之前的处理方式都是一样的。所以,你总可以在使用特殊符号之前,从HTML页面中得到编码信息:
1
2
3
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
然而,这个元标签必须是头标记中的第一个元素,因为浏览器在看到这个标签时,会立即停止原有的解析,而改为采用你指定的编码进行解析。
如果浏览器在http头和html标签中都没有找到Context-Type标记,会怎么做呢?IE浏览器的做法比较有趣:他试图基于各种字节在不同语言的典型的文本、典型编码中的出现频率去猜测你的语言和编码。因为,各种老的8位的编码,习惯把他们本地的字母放在128-255之间不同的范围内,同时因为每种人类语言都有自己的不同的字母使用典型直方图,所以,这种猜测确实在某种程度中可行。这的确有写些诡异,以至于使一个不知道需要在header中添加Content-Type信息的天真web页面的开发者,发现不了页面的问题。直到有一天,他们开发了一些不完全符合字符频率分部的本地语言的页面,IE浏览器认为是韩语并且据此展现,这说明,Postel法案关于”保守的给予,自由的获取”(OneCoder注:conservative in what you emit and liberal in what you accept)的观点,对于工程理论来说是荒谬的。那么,该网站可怜的读者该怎么办?本来网站是用保加利亚语写的,却用韩语展现。(甚至还是无法理解的韩语)。如果他知道,他可以通过查看->编码菜单尝试不同的编码,(那里对于东欧的编码就有一大堆),直到页面开始显示正常。当然,大部分人们并不知道去这么做。

在我们公司发布的网站管理软件,CityDesk的最新版中,我们决定采用UCS-2来存储Unicode,这正式VistualBasic,COM,和WindowsNT/2000/XP采用的表示本地字符串的方式。在C++的代码中,我们用wchar_t(“wide char”)来声明字符串,而非使用char,并且使用wcs函数而非str函数。(例如:wcscat和wcslen来代替strcat和strlen)。为了在C语言中声明一个UCS-2的字符串,你必须在前面加上一个L,变成:L”Hello”。
当CityDesk发布网页版的时候,变成了这些年浏览器普遍支持良好的UTF-8编码。这就是Joel on Software 网站29种不同语言版本的编码方式,我还没有听说任何一个人有编码问题。
这篇文章已经好长了。(OneCoder注:确实太长了,累吐血了。) 我不可能面面俱到的介绍关于字符编码和 Unicode的一切,但是,我仅希望,如果你读到了这里,你可以拥有足够知识去开发程序了。用抗生素治病,而不要用水蛭和符咒了,剩下的,就靠你自己了,孩子。
OneCoder注:头一次翻译,感觉翻译的很生硬,错误也再所那面,望多多指教。
所有代码已上传至Github:https://github.com/lihongzheshuai/yummy-code
GESP 学习专题站:GESP WIKI
"luogu-"系列题目可在洛谷题库进行在线评测。
"bcqm-"系列题目可在编程启蒙题库进行在线评测。
欢迎加入:Java、C++、Python技术交流QQ群(982860385),大佬免费带队,有问必答
欢迎加入:C++ GESP/CSP认证学习QQ频道,考试资源总结汇总
欢迎加入:C++ GESP/CSP学习交流QQ群(688906745),考试认证学员交流,互帮互助
