MySQL Cluster 初用初测小结
基于上篇搭建的环境,验证一些基本功能和性能需求。这里先说一下功能使用的问题。OneCoder也是第一次用。摸索着来,仅做一个记录。
从部署图就可知道,对数据库的请求操作发生在SQL节点上。为了达到试验效果,这里又追加了一个sql节点。现在集群环境如下:
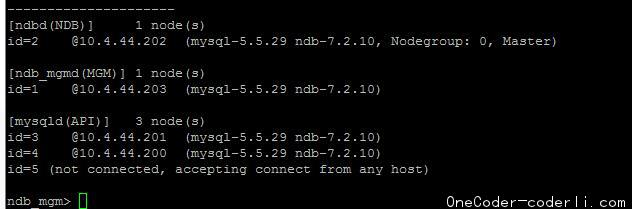
在追加的过程中,发现MySQL Cluster对启动顺序要求严格,在没考虑热部署方案的情况下,必须停止了所有节点,重新按照management->data->sql的顺序启动节点。
现在测试对表的创建和修改的自动同步:
在任意SQL节点执行:(这里选择44.200节点)
create table bigdata_cluster(id int primary key, name varchar(20)) engine=ndbcluster default charset utf8;
创建表,注意表的引擎一定要指定ndbcluster,在201节点查看
show tables;
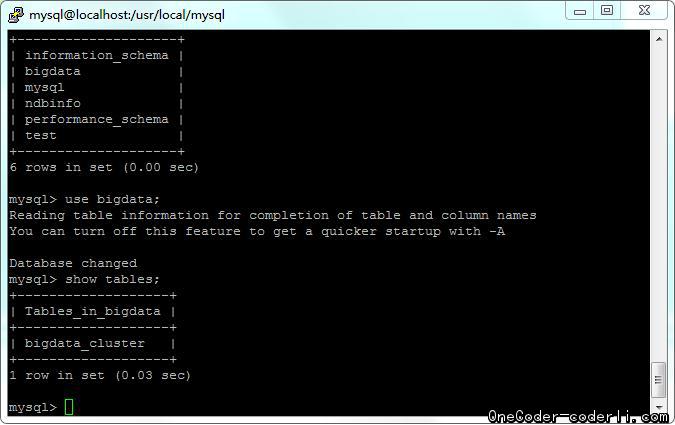
发现已经可以同步查询了。其实本来底层data节点对上层就是透明的,自然可以查到。多sql节点,就可以起到负载均衡的效果。
调整表和数据插入,都跟传统的MySQL方式相同,不再赘述,同样也是可以做到实时同步的,这里也测过了。下面通过JDBC代码测试下API操作的效果,同时也想灌入100w的数据,进行一下效率测试和对比。
在测试前,OneCoder先用SQLyog工具,测试了一下数据库远端访问权限,发现果然没有。在一个节点grant all了一下以后,却发现另一个节点仍然无法访问,搜索才知,原来MySQL Cluster的用户权限默认不是共享的,进行如下设置,在mysql终端执行:
mysql> SOURCE /usr/local/mysql/share/ndb_dist_priv.sql; mysql> CALL mysql.mysql_cluster_move_privileges();
即可完成权限共享,现在在一个终端设置的权限就是集群共享的了。在用SQLYog测试,果然均可以链接了。下面开始开发JDBC链接MySQL的代码:</p>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
/**
* 向数据库中插入数据
*
* @param conn
* @param totalRowCount
* @param perRowCount
* @param tableName
* @author lihzh(OneCoder)
* @throws SQLException
* @date 2013-1-17 下午1:57:10
*/
private void insertDataToTable(Connection conn, String tableName,
long totalRowCount, long perRowCount) throws SQLException {
conn.setAutoCommit(false);
long start = System.currentTimeMillis();
String sql = "insert into " + tableName + " VALUES(?,?,?)";
System.out.println("Begin to prepare statement.");
PreparedStatement statement = conn.prepareStatement(sql);
for (int j = 0; j < TOTAL_ROW_COUNT / BATCH_ROW_COUNT; j++) {
long batchStart = System.currentTimeMillis();
for (int i = 0; i < BATCH_ROW_COUNT; i++) {
long id = j * BATCH_ROW_COUNT + i;
String name_pre = String.valueOf(id);
statement.setLong(1, id);
statement.setString(2, name_pre);
statement.setString(3, name_pre);
statement.addBatch();
}
System.out.println("It's up to batch count: " + BATCH_ROW_COUNT);
statement.executeBatch();
conn.commit();
long batchEnd = System.currentTimeMillis();
System.out.println("Batch data commit finished. Time cost: " + (batchEnd - batchStart));
}
long end = System.currentTimeMillis();
System.out.println("All data insert finished. Total time cost: " + (end - start));
}
开始设置BATCH_ROW_COUNT为5w,结果报错:
java.sql.BatchUpdateException: Got temporary error 233 'Out of operation records in transaction coordinator (increase MaxNoOfConcurrentOperations)' from NDBCLUSTER
意思比较明显,超过了MaxNoOfConcurrentOperations设置的值。该值默认为:32768。你可以通过修改config.ini里的配置改变默认值。不过有人提到,修改该值的同事,你也需要修改
MaxNoOfLocalOperations的值,并且建议后者的值超过前者值10%左右(1.1倍)。
这里为了避免麻烦,我们直接将代码的里预设值调小到2w,再运行代码。
Begin to prepare statement.
It's up to batch count: 20000
Batch data commit finished. Time cost: 20483
It's up to batch count: 20000
Batch data commit finished. Time cost: 19768
It's up to batch count: 20000
Batch data commit finished. Time cost: 20136
It's up to batch count: 20000
Batch data commit finished. Time cost: 19958
…….
java.sql.BatchUpdateException: The table 'bigdata_cluster' is full
无语……表满了。共写入了88w条数据。每次batch写入时间稳定。再测试条件查询耗时:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/**
* 查询特定的一个或者一组数据,打印查询耗时
*
* @param conn
* @param tableName
* @author lihzh
* @throws SQLException
* @date 2013-1-17 下午4:46:20
*/
private void searchData(Connection conn, String tableName) throws SQLException {
long start = System.currentTimeMillis();
String sql = "select * from " + tableName + " where name = ?";
PreparedStatement statement = conn.prepareStatement(sql);
statement.setString(1, "300");
ResultSet resultSet = statement.executeQuery();
resultSet.first();
System.out.println("Name is: " + resultSet.getObject("name"));
long end = System.currentTimeMillis();
System.out.println("Query one row from 88w record cost time: " + (end - start));
}
通过另一个sql节点,根据没有索引的name字段查询耗时约1.4s,有索引的id查询耗时20ms左右。
再新建一个表,发现什么数据再也无法写入,看来是数据节点全局容量限制导致的。修改config.ini文件中的
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=18M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough for
# this example Cluster setup.
分别改为1400和384M。重启集群。再通过
ndb_mgm> all report memoryusage
命令查看使用情况,

似乎恢复了正常。再向新表写入数据,成功。
测试删除数据,又遇到提示:
ERROR 1297 (HY000): Got temporary error 233 'Out of operation records in transaction coordinator (increase MaxNoOfConcurrentOperations)' from NDBCLUSTER
看来真的得调整MaxNoOfConcurrentOperations参数的大小了。根据虚拟机内存情况(据说1约需要1kb内存。因此10w,大约100m内存),调整如下:
MaxNoOfConcurrentOperations=300000
MaxNoOfLocalOperations=330000
重启,测试删除11w数据,通过。同时,再次测试向新表写入100w条数据,以20w为一组,也顺利通过了。
It's up to batch count: 200000
Batch data commit finished. Time cost: 268642
It's up to batch count: 200000
Batch data commit finished. Time cost: 241301
It's up to batch count: 200000
Batch data commit finished. Time cost: 209329
It's up to batch count: 200000
Batch data commit finished. Time cost: 207634
It's up to batch count: 200000
Batch data commit finished. Time cost: 241746
All data insert finished. Total time cost: 1168703
目前的使用情况大致如此,接下来OneCoder打算测试一下集群节点添加和数据自动分区读写情况。等有了结论在与大家分享。
所有代码已上传至Github:https://github.com/lihongzheshuai/yummy-code
GESP 学习专题站:GESP WIKI
"luogu-"系列题目可在洛谷题库进行在线评测。
"bcqm-"系列题目可在编程启蒙题库进行在线评测。
欢迎加入:Java、C++、Python技术交流QQ群(982860385),大佬免费带队,有问必答
欢迎加入:C++ GESP/CSP认证学习QQ频道,考试资源总结汇总
欢迎加入:C++ GESP/CSP学习交流QQ群(688906745),考试认证学员交流,互帮互助
