【CSP】CSP-J 2020真题 | 直播获奖 luogu-P7072 (适合GESP四级及以上考生练习)
CSP-J 2020真题-直播获奖,桶排序(计数排序)考点,重点考察对于动态数据集合的快速查询和时间复杂度优化能力,适合GESP四级及以上考生练习,难度⭐⭐☆,洛谷难度等级普及−。
P7072 [CSP-J 2020] 直播获奖
题目要求
题目描述
NOI2130 即将举行。为了增加观赏性,CCF 决定逐一评出每个选手的成绩,并直播即时的获奖分数线。本次竞赛的获奖率为 $w\%$,即当前排名前 $w\%$ 的选手的最低成绩就是即时的分数线。
更具体地,若当前已评出了 $p$ 个选手的成绩,则当前计划获奖人数为 $\max(1, \lfloor p \times w \%\rfloor)$,其中 $w$ 是获奖百分比,$\lfloor x \rfloor$ 表示对 $x$ 向下取整,$\max(x,y)$ 表示 $x$ 和 $y$ 中较大的数。如有选手成绩相同,则所有成绩并列的选手都能获奖,因此实际获奖人数可能比计划中多。
作为评测组的技术人员,请你帮 CCF 写一个直播程序。
输入格式
第一行有两个整数 $n, w$。分别代表选手总数与获奖率。
第二行有 $n$ 个整数,依次代表逐一评出的选手成绩。
输出格式
只有一行,包含 $n$ 个非负整数,依次代表选手成绩逐一评出后,即时的获奖分数线。相邻两个整数间用一个空格分隔。
输入输出样例 #1
输入 #1
1
2
10 60
200 300 400 500 600 600 0 300 200 100
输出 #1
1
200 300 400 400 400 500 400 400 300 300
输入输出样例 #2
输入 #2
1
2
10 30
100 100 600 100 100 100 100 100 100 100
输出 #2
1
100 100 600 600 600 600 100 100 100 100
说明/提示
样例 1 解释
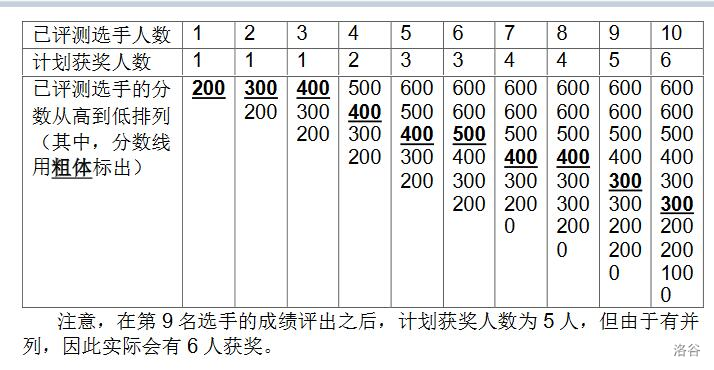
【数据规模与约定】
各测试点的 $n$ 如下表:
测试点编号 $n=$ $1 \sim 3$ $10$ $4 \sim 6$ $500$ $7 \sim 10$ $2000$ $11 \sim 17$ $10^4$ $18 \sim 20$ $10^5$ 对于所有测试点,每个选手的成绩均为不超过 $600$ 的非负整数,获奖百分比 $w$ 是一个正整数且 $1 \le w \le 99$。
在计算计划获奖人数时,如用浮点类型的变量(如 C/C++ 中的
float、double,Pascal 中的real、double、extended等)存储获奖比例 $w\%$,则计算 $5 \times 60\%$ 时的结果可能为 $3.000001$,也可能为 $2.999999$,向下取整后的结果不确定。因此,建议仅使用整型变量,以计算出准确值。
题目分析
本题是一道具有明显提示的排序/统计类题目,要求我们在每次加入一个新成绩时,动态计算并输出当前的及格分数线。
解题思路分析:
- 题目核心诉求:
- 给定 $n$ 个分数,随着一个个分数的输入,我们需要实时知道排名前 $\max(1, \lfloor p \times w\% \rfloor)$ 这个名次对应的分数。
- 比如现在输入了 $p$ 个数,$w=60$,我们需要知道当前这 $p$ 个数中排名前 $\lfloor p \times 60 \div 100 \rfloor$(至少取 1)的分数是多少。如果用
sort()对每一次读入进行快速排序,时间复杂度将达到 $O(n^2 \log n)$,显然对于最大 $10^5$ 的数据规模会超时(TLE)。
- 发现题目的巨大漏洞(限制条件):
- 仔细审题,注意到提示中的一句极其关键的话:“每个选手的成绩均为不超过 $600$ 的非负整数”。
- 这就意味着,所有可能出现的分数种类被严格限制在了
0到600这 601 个数值之内! - 面对此类“数据范围较小但数据量极大”的题目,桶排序(计数排序) 是不二之选。
- 桶排序(计数思想)应用:
- 创建一个大小为 605 的数组
bucket[605](稍微开大一点防止容量越界),用来记录每个分数出现的次数。 - 每次读入一个新成绩
score时,这一个桶的计数就加一:bucket[score]++。 - 然后,我们需要寻找当前前 $k$(也就是当前的计划获奖人数)名对应的分数线。既然成绩范围是
0到600,我们只需从满分600开始,从上往下遍历每个分数桶,不断累加人数。 - 当累加的人数大于或等于我们计划的获奖人数 $k$ 时,当前遍历到的这个分数就是我们要找的分数线!
- 创建一个大小为 605 的数组
- 时间复杂度与误差防备:
- 每次遍历桶的长度最多为 601 次,这是常数级别的操作。
- 总共有 $n$ 此读取操作,因此总时间复杂度为 $O(600n)$,在 $n=10^5$ 的规模下最多只需要运算 6 千万次左右,远低于现代 CPU 1 秒内上亿次的运算能力,可以轻松通过所有测试点。
- 避免浮点误差的问题:由于提示建议仅用整型来避免小数取整误差,我们在求目标人数时,直接用整型运算
p * w / 100(先乘后除计算)就可以天然实现向下取整。
示例代码
桶排序解法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#include <iostream>
#include <algorithm>
int bucket[605]; // 定义一个足够装下 0-600 各分数的桶数组,初始默认全为 0
int main() {
int n, w;
std::cin >> n >> w;
for (int p = 1; p <= n; p++) {
int score;
std::cin >> score;
// 步骤 1:把当前成绩装入对应的桶里,也就是该分数的人数加 1
bucket[score]++;
// 步骤 2:算出当前的计划获奖人数
// 注意仅使用整型计算,先乘后除防止浮点误差且实现向下取整
int plan_num = std::max(1, p * w / 100);
// 步骤 3:从最高分 600 向下查找分数线
int sum = 0; // 累计已统计的高分人数
for (int i = 600; i >= 0; i--) {
sum += bucket[i]; // 将该分数段的人数加入总计
// 如果累计的优秀人数已经达到或超过了目标获奖人数
if (sum >= plan_num) {
std::cout << i << " "; // 当前遍历到的分数就是我们需要找的分数线
break; // 找到即可停止循环,处理下一个
}
}
}
std::cout << std::endl; // 最后输出换行以规范格式
return 0;
}
所有代码已上传至Github:https://github.com/lihongzheshuai/yummy-code
GESP 学习专题站:GESP WIKI
"luogu-"系列题目可在洛谷题库进行在线评测。
"bcqm-"系列题目可在编程启蒙题库进行在线评测。
欢迎加入:Java、C++、Python技术交流QQ群(982860385),大佬免费带队,有问必答
欢迎加入:C++ GESP/CSP认证学习QQ频道,考试资源总结汇总
欢迎加入:C++ GESP/CSP学习交流QQ群(688906745),考试认证学员交流,互帮互助
